
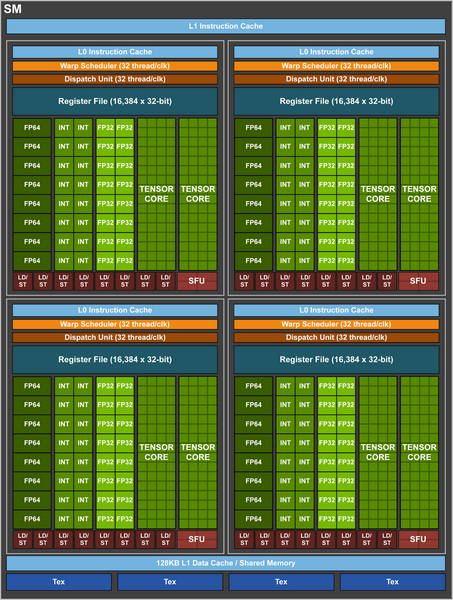
Представлен GPU GV100 поколения Volta: 5376 ядер CUDA, 21,1 млрд транзисторов и 672 дополнительных ядра Tensor Cores
В апреле прошлого года Nvidia представила GPU GP100 поколения Pascal, содержащий 15 млрд транзисторов и 3840 ядер CUDA. Тогда он казался чем-то невероятным, но сейчас ускорители GeForce GTX 1080 Ti и Titan Xp содержат практически такой же GPU GP102 и их без проблем можно купить.
Поэтому пришло время представить нового монстра. И им стал графический процессор GV100 поколения Volta. Напомним, это не первый анонс данной архитектуры. Ещё в сентябре прошлого года Nvidia представила SoC Xavier с GPU поколения Volta, но она всё равно выйдет на рынок лишь в следующем году.

Итак, GV100 — новый флагманский GPU Nvidia. Он состоит уже из 21,1 млрд транзисторов и включает 5376 ядер CUDA! Да, примерно через год или чуть больше на рынке появятся потребительские видеокарты компании с приблизительно такими же параметрами, но сейчас характеристики нового GPU впечатляют.
Как и GP100 в своё время, GV100 не предназначен для потребительских видеокарт. На основе этого GPU будут создавать профессиональные ускорители для рабочих станций, серверов и так далее.
GV100 будут производить по 12-нанометровому техпроцессу на мощностях TSMC. Площадь монструозного GPU составляет 815 мм². Для сравнения, площадь GP100 составляет «всего» 610 мм². Судя по всему, GV100 является самым крупным графическим процессором за всю историю.
GV100 располагается на одной подложке с памятью HBM2, как и предшественник. Только теперь её пропускная способность достигает 900 ГБ/с, но объём почему-то уменьшили с 32 до 16 ГБ, что выглядит странно.
Также GV100 выделяется тем, что содержит дополнительные вычислительные блоки. Речь о 672 блоках Tensor Cores, которые предназначены для вычислений, происходящих в рамках процессов машинного обучения и глубокого обучения. Это первый GPU с подобной архитектурой на рынке и потребительский аналог, который, вероятно, назовут GV102, явно этого блока не получит. К слову, производительность именно в операциях машинного и глубокого обучения указана равной 120 TFLOPS.
Что же касается классической производительности, то она достигает 7,5 TFLOPS (FP64) и 15 TFLOPS (FP32).

Как и в прошлом году, нам сразу представили и ускоритель Tesla V100 на основе GV100, но только с 5120 активными ядрами CUDA и 640 ядрами Tensor Cores. Он выполнен в виде модуля с интерфейсом NVLink второго поколения с пропускной способностью 300 ГБ/с, но позже, вероятно, появится и модификация в виде стандартной платы расширения с интерфейсом PCIe. Также известно, что GPU в данном случае работает на частоте до 1455 МГц. Учитывая неимоверную сложность данного графического процессора, можно предположить, что потребительские GPU будут работать на ещё более высоких частотах, то есть относительно решений поколения Pascal частоты должны вырасти. TDP ускорителя составляет 300 Вт.
Источник:
Nvidia
WCCF Tech